Optimizing F1 Performance: A Pairwise Ranking Approach for Drivers and Teams
🏎️ Project Summary & Skills Used
🏆 Project Overview
This project applies Integer Linear Programming (ILP) to solve a real-world sports ranking problem. We developed a two-stage optimization system to establish a comprehensive ranking of F1 drivers and their respective teams based on multi-race results, using a novel pairwise comparison model.
Key Skills Used and Developed
Operations Research: Formulating and implementing a complex optimization model (Original and Extended).
Programming & Solvers: Implementing and solving the ILP models using AMPL/CPLEX.
Data Handling: Gathering, processing, and integrating real-world data into model parameters.
Analysis: Interpreting optimized rankings and demonstrating the validity of the pairwise ranking method.
🔧 Project Development Process
The Ranking Challenge
Our original goal was to objectively rank F1 drivers based on their performance consistency across multiple races, moving beyond simple point totals.
Design Evolution (Model Extension)
After successfully solving the Original Driver Model, we extended the model to rank the F1 Teams themselves. This included introducing the parameter \(A_{d,t}\) (TeamOf), which links each driver to their constructor. Extending the model added substantial value and required adapting the pairwise inversion logic to operate on driver-to-team relationships.
Roadblocks and Solutions
Data Synthesis: A fully formatted dataset for all 24 races was not readily available. Mark gathered, cleaned, and synthesized the race result data directly from the F1 website (e.g., https://www.formula1.com/en/results/2024/drivers) to build the input parameters.
Missing Race Data: Not all drivers appear in all races due to substitutions. Our pairwise comparison structure naturally handled this variability by summing inversions (\(\Sigma_{r\in R}\)) only across the relevant races for each driver.
✨ Key Features & Model Formulations
1. Original Driver Ranking Model
This ILP minimizes the total number of “inversions”—instances where a driver is ranked lower overall but finished ahead of a higher-ranked driver in a specific race.
Objective Function: \[ \min \sum_{r\in R}\sum_{i\in D}\sum_{j\in D}y_{r,i,j} \]
Sets:
- R: Set of races (1, 2, …, 24)
- D: Set of drivers
- \(K\): Set of possible final ranking positions (\(K=\{1,2,...,|D|\}\))
Parameters:
- \(P_{d,r}\): Finishing position of driver \(d\) in race \(r\)
Decision Variables:
\(x_{d,k} \in \{0, 1\}\): 1 if driver \(d\) is assigned rank \(k\), 0 otherwise
\(p_{d}\): Final rank assigned to driver \(d\)
\(y_{r,i,j} \in \{0, 1\}\): 1 if driver \(i\) finished ahead of driver \(j\) (\(P_{i,r}<P_{j,r}\)), 0 otherwise
Constraints: 1. Unique Rank Assignment (Driver):
\[\sum_{k\in K}x_{d,k}=1 \quad \forall d \in D\] 2. Unique Rank Assignment (Rank):
\[\sum_{d\in D}x_{d,k}=1 \quad \forall k \in K\] 3. Calculate Final Rank:
\[p_{d}=\sum_{k\in K}k\cdot x_{d,k} \quad \forall d \in D\] 4. Pairwise Constraint (Big M):
\[p_{i}+1\le p_{j}+M\cdot y_{r,i,j} \quad \forall r \in R, i, j \in D\]
Final Driver Ranking Output:
Final optimized rankings placed Max Verstappen (1st), Lando Norris (2nd), Oscar Piastri (3rd).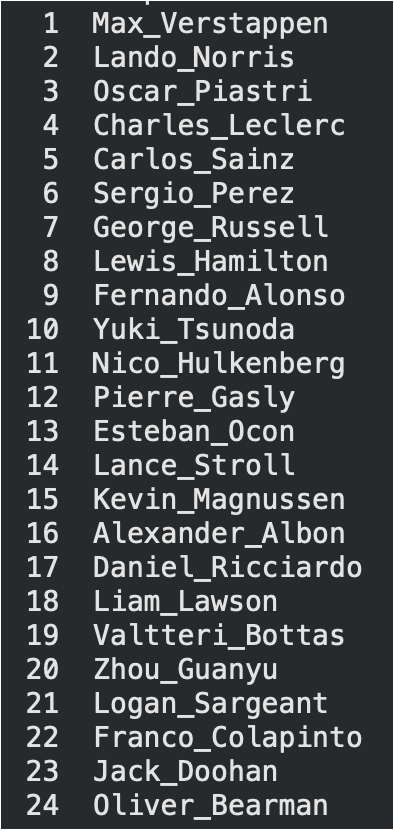
Driver Ranking Results
2. Extended Team Ranking Model
This extension applies the same minimization logic to rank the F1 teams, linking individual driver results to the overall team ranking.
Objective Function: \[ \min \sum_{r\in R}\sum_{i\in D}\sum_{j\in D}y_{r,i,j} \]
New/Updated Sets & Parameters:
- T: Set of teams
- \(K\): Set of possible final ranking positions for teams (\(K=\{1,2,...,|T|\}\))
- \(A_{d,t}\): Assignment of driver \(d\) to team \(t\) (parameter)
New/Updated Decision Variables:
- \(x_{t,k} \in \{0, 1\}\): 1 if team \(t\) is assigned rank \(k\), 0 otherwise
- \(p_{t}\): Ranking assigned to team \(t\) after optimization
Constraints: 1. Unique Rank Assignment (Team):
\[\sum_{k\in K}x_{t,k}=1 \quad \forall t \in T\] 2. Unique Rank Assignment (Rank):
\[\sum_{t\in T}x_{t,k}=1 \quad \forall k \in K\] 3. Calculate Final Rank:
\[p_{t}=\sum_{k\in K}k\cdot x_{t,k} \quad \forall t \in T\] 4. Pairwise Constraint (Team-Based Big M):
\[P(\text{team of racer } i)+1\le P(\text{team of racer } j)+M\cdot Y_{r,i,j}\]
3. Data Insights and Optimized Results
Raw Data Snapshot: A sample of the synthesized race data (Bahrain GP) showing the key parameters: finishing position, racer ID, and team ID.
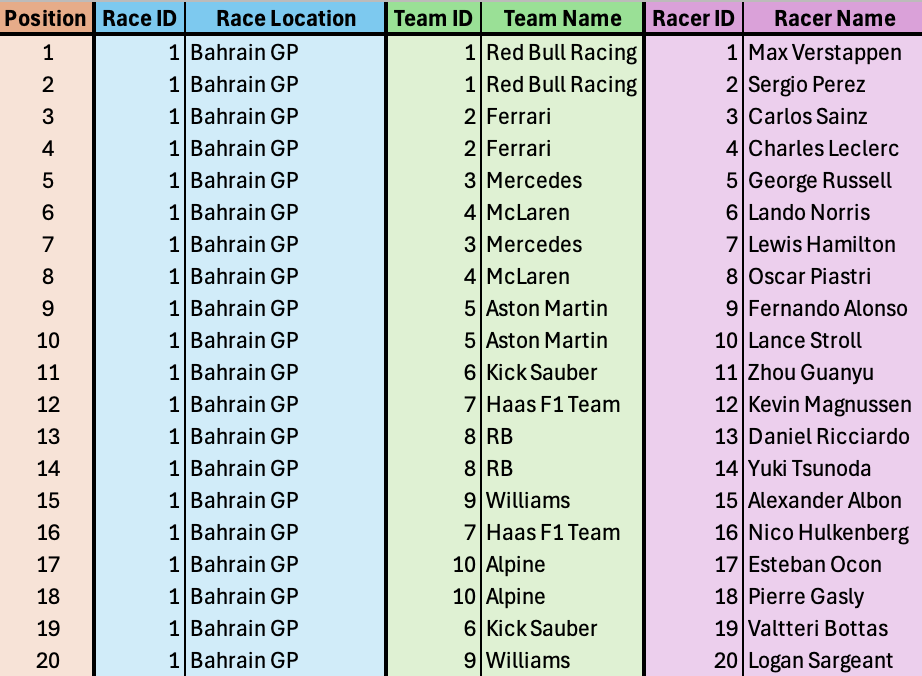
Final Team Ranking Output:
Final optimized rankings placed Red Bull (1st), McLaren (2nd), Ferrari (3rd).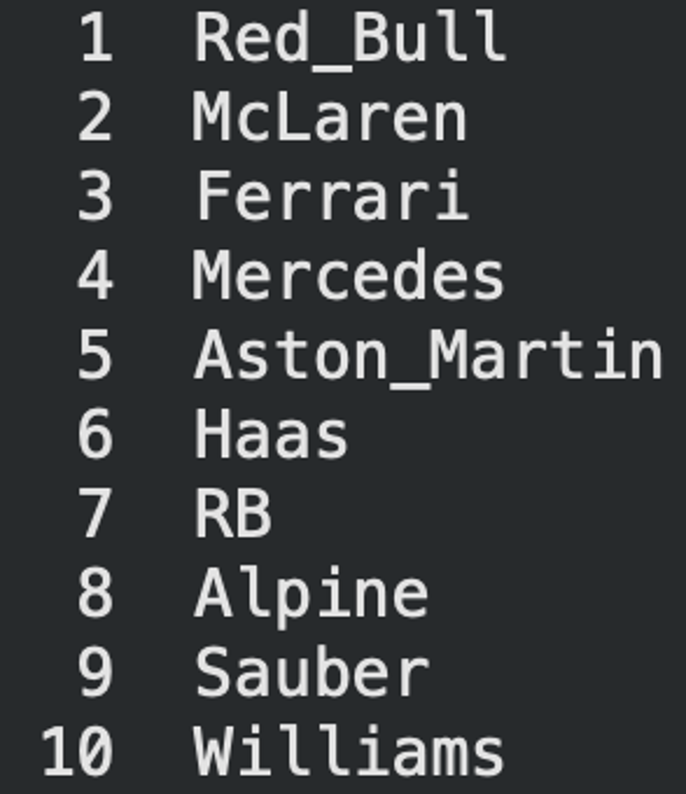
Team Ranking Results
4. Key Takeaways
- Pairwise comparison models provide accurate aggregated rankings across many races.
- Race-to-race variation reinforces the need for inversion-based aggregate metrics.
🧠 Reflection
Individual Experience
Working on this project was a powerful way to connect theoretical optimization concepts to a real applied ranking problem.
Learning & Growth:
I significantly strengthened my skills in optimization modeling. Building the initial driver model and extending it to teams required careful thinking about structure, constraints, and the logic behind pairwise comparisons. Implementing everything in AMPL and solving with CPLEX gave me hands-on experience with solver behavior and constraint validation.My Contribution:
I led the model development, including all AMPL coding, debugging, and adapting the inversion logic for both drivers and teams. Ensuring the Big-M constraints behaved correctly across all races was one of the most technical parts of the project.Teamwork and Debugging:
Mark handled the data gathering and synthesis for all 24 races, which was essential for building the parameter matrices the model relies on. Our debugging process focused heavily on validating that the pairwise constraints (like \(p_{i}+1 \le p_{j}+M y_{r,i,j}\)) were working as intended, reinforcing how important clear model structure is for OR work.